End-User Experience: Score and Store, Don’t Ignore

It’s the tale as old as timestamps:
- A random user complains of a random performance problem
- When someone is available to assist the user, the problem is no longer occurring
- The available data doesn’t provide any real clues
- Wait a while. Repeat.
Why is this story still being told? With all the advancements that have been made in network and application performance management, why isn’t this an old chestnut that starts with, “Once upon a time,” instead of something we’re reading in a support ticket that was just opened this morning?
Part of the problem can be attributed to our old friend, volume. No, not the knob that goes to 11, but the sheer size, mass, magnitude, bigness of the haystack of raw data and KPIs that we must sort through in order to find the needle. And of course, to further complicate the story, the “haystack” may have been moved or redistributed throughout the cloud, mixed-metaphorically speaking.
As a result of having more data in more places, many vendors have settled on the approach of increased reliance on various forms of data pruning and summarization. Raw data is selectively gathered and retained for very short periods of time and then things quickly get rolled up into KPIs. Unfortunately, aggregated data = aggravated users when it comes to solving the intermittent problem described above.
If you choose to ignore the small individual transactions and conversations and focus only on summary data, you may well find yourself repeating and reliving the same old story. Let’s use a real-world example to illustrate how to change this narrative.
Chapter One: Score Each Application Tier

In order to truly understand end-user experience and rapidly isolate problem domains, we must look at the individual components of composite services. In this case, the Oracle TNS component of a multi-tier application is beginning to show signs of performance degradation. This is made obvious by looking at one simple User Experience Score. Now we have both problem validation and domain isolation.
Chapter Two: Score Each Server

Now that we’ve focused in on a single application tier, we need to understand the performance of each of the servers associated with that tier. In this case, one of five servers is clearly manifesting unusual behavior. The obvious question becomes, how many end-users are impacted by this performance degradation?
Chapter Three: Score Each Conversation

Good news: One affected user. Probably that same random user that started this whole story…
So, we have domain, device, scope and impact. Can we further isolate the problem?
Chapter Four: Store Each Conversation
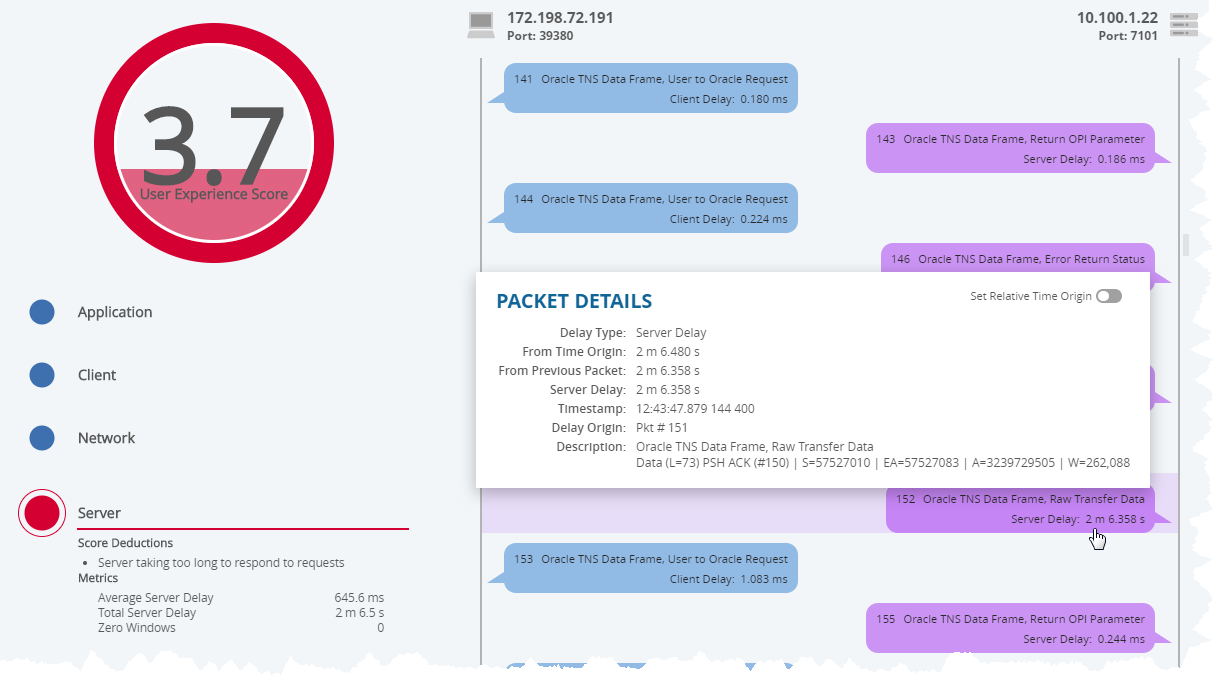
For this client query, the server took over two minutes to respond. We stored and scored each user transaction and that has made all the difference.
Compare this scenario and outcome to the one described at the outset. Our story has changed from one where the support desk is wondering whether the user ever really had a problem, and the user is wondering why they bothered calling the support desk, to one where we’ve validated and isolated the issue.
Don’t settle for summaries. Don’t ignore the things that matter. Your world may not be transformed into the stuff found in fairy tales, but you will enjoy far more happy endings.
To learn more about how VIAVI can help you address user experience issues, visit our website. Ready to see the solution in action? Contact us today for a VIAVI Observer demonstration.


{kind=link}