How AI is Pushing the Boundaries of Data Center Networks

Artificial intelligence is everywhere, from the smart assistant in your phone to the massive language models (LLMs) creating content online. LLMs like GPT-5, LLAMA-4 or Gemini 2.5 are not just larger versions of their predecessors; using Mixture-of-Experts (MoE) architecture, they’re on an entirely new scale, trained on petabytes of data with arguably trillions of parameters. But as AI gets smarter, exponential increase in the size and complexity of the AI models is putting an unprecedented strain on data center networks, creating major bottlenecks. The networking world is racing from 400G speeds to 800G, and now to 1.6T in just a few years — all to keep up with AI’s appetite for data.
Why today’s networks are too slow for AI
AI workloads, especially the training of LLMs, are fundamentally different from traditional data center tasks. They are distributed across thousands of GPUs that must work together as one. Think of a modern AI data center as a huge factory. The workers are the thousands of powerful GPUs and processors that handle the complex calculations. For them to work together on a single task, they need to constantly share vast amounts of data over the data center network. This creates a need for an incredible amount of east-west traffic, which is data moving between servers in the same data center.
- Training Time Matters –Training a massive AI model can take weeks or even months. The network’s speed is a crucial factor here. If the network can’t keep up with the GPUs, these expensive processors sit idle, waiting for data. A faster network means less GPU idle time and shorter training cycles.
- Data Transfers Are Massive – AI models consume petabytes of training data moved continuously over the network. Even a single lost packet could result in a job failure, wasting weeks of compute time. That’s why these networks need both extreme bandwidth and lossless transmission with enough headroom to handle retries.
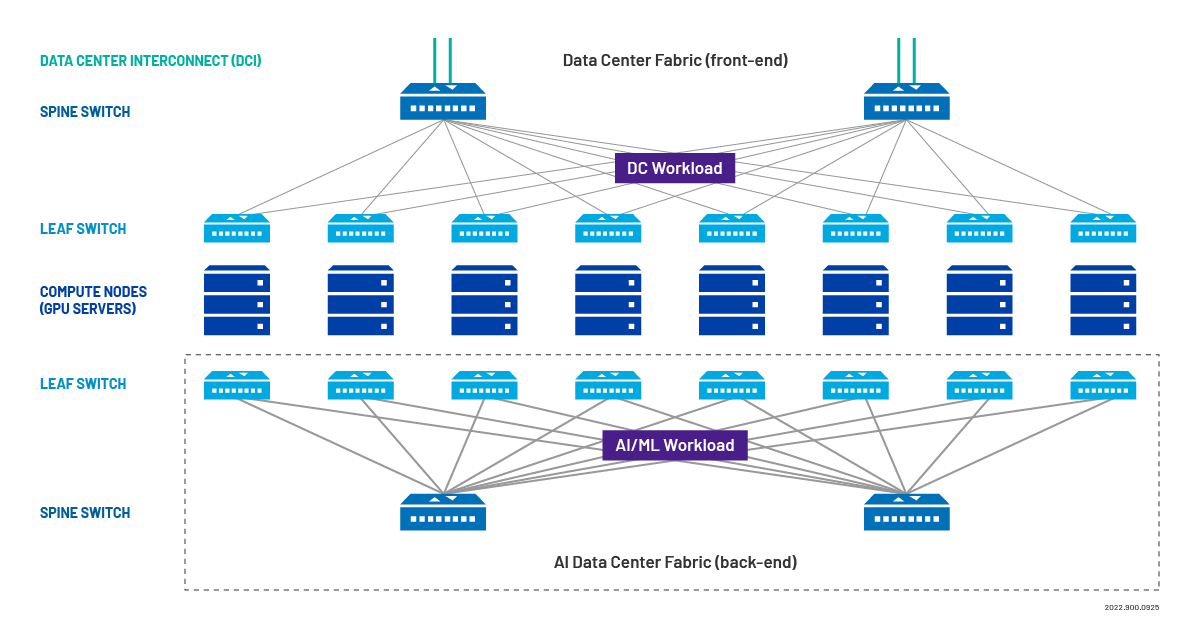
AI data centers are structured differently than traditional data centers.
Enter 1600G Ethernet – AI’s new best friend
1600G Ethernet, also known as 1.6T, is designed to be the backbone of the next-generation AI data center. It provides the necessary bandwidth and performance to overcome the limitations of older networks. 1.6T Ethernet, defined by the IEEE 802.3dj standard, uses 200 Gb/s per lane and provides twice the total bandwidth of 800G, enabling much faster data transfer. This high throughput ensures that data gets to the GPUs when they need it, keeping them running at peak efficiency.
Faster networks means smarter AI
The robust, high-speed network like 1600G Ethernet removes previous constraints and unlocks new possibilities for AI development. With the bottleneck removed, AI engineers can now design and train even larger and more complex AI models. These powerful new models, in turn, will be capable of processing even greater volumes of data and will inevitably create new demands for even faster networks, perpetuating the cycle.
See us at ECOC25
Catch our 1.6Tb test solution, the ONE LabPro® ONE-1600, in action at ECOC 2025, Sept 29-Oct 1, stand C3113.
Not attending? No worries! Submit a meeting request and we’ll connect at your convenience.
Schedule a Meeting: VIAVI at ECOC 2025
Real-world testing insights – view our 1.6Tb content
- VIAVI ONE LabPro 1.6Tb Turns One
- 224G SERDES – The Foundation of Hyperscale Data Centers, AI and HPC Applications
- 1.6Tb/s Module Development and Validation – Initial Impressions
- Anatomy of a 1.6Tb Module
- Testing at 1.6T – Enabling AI, ML, HPC and Quantum Applications at Scale
- ONE-1600: Cutting-edge, Field-proven 1.6T Testing Solution
- ONE-1600 Accelerates Development of 1.6T Optics at Scale
- Scale with Confidence-Delivering on the Promise of the AI Revolution


{kind=link}