Key Challenges for Next-Gen AI Inference Networks and Building Resilience in 1.6T Fabric

If there is one aspect of AI that challenges high-bandwidth networking more than any other, it is training.
However, with the growth of applications that depend on inference performance, inference is quickly catching up and placing even greater strain on the network. Compounding this are rising usage volumes, test-time scaling, mixture-of-experts architectures, and the use of dedicated nodes for prefill and decode, each adding its own demand on network capacity.
High-volume inference server deployments demand increasingly high-capacity inter-rack communications, which goes hand in hand with the extreme resilience needed to handle high connection rates and concurrency. On top of this, those transfers need to use higher levels of security to prevent increasingly sophisticated attacks. This all leads to heavy investment on several fronts.
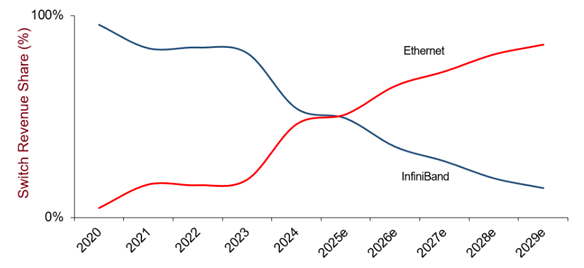
Scaling to 1.6T Ethernet
Speed is one part of the solution. 1.6T Ethernet links provide additional capacity, and not just for the “elephant flows”, which are encountered during training when back-propagation algorithms perform all-to-all updates across all the nodes taking part in a training batch. For more general use, going beyond 800G Ethernet provides the headroom needed to avoid congestion in inferencing-oriented networks when connecting spine switches to the leaf nodes managing groups of scale-up AI servers.
The shift to 1.6T links coincides with the introduction of protocols, such as Ultra Ethernet, which introduce mechanisms for traffic control to deliver more efficient operation for AI workloads. In doing so, these protocols cut down on the congestion that can arise when traffic spikes hit traditional Ethernet equipment. However, they also introduce novel requirements that require careful analysis and testing in production systems.
Ultra Ethernet’s rise is the latest step in a broader move away from InfiniBand, which has traditionally been the fabric of choice for high-bandwidth, low-latency interconnection. Version 2 of remote direct memory access (RDMA) over Converged Ethernet (RoCE) effectively embeds InfiniBand’s transport in the most recent versions of Ethernet.
Lossless Transport
RoCEv2 relies on lossless transport combined with strict in-order packet delivery, which helps simplify the organization of nodes cooperating on AI tasks. Existing Ethernet switches guarantee these characteristics mainly with priority flow control (PFC), with this facility demanding, in turn, the ability to manage this traffic as a separate class and the use of sufficiently large, dedicated buffers. However, this approach also risks incurring congestion on heavily used paths with in-order delivery typically limiting the choice of paths packets can take. More dynamic systems need the ability to spread loads across more paths, though this is more complex to achieve.
Ultra Ethernet addresses these issues in a way that ensures packets can travel over conventional Ethernet networks. In principle, Ultra Ethernet traffic does not need to run in its own traffic class – though most AI networks can benefit from segregated traffic classes. To handle in-order delivery, the protocol defines fabric endpoints as logical entities that sit at each end of the transport layer needed for reliable communication between two nodes, with these working in concert with mechanisms such as equal-cost multipathing (ECMP). The use of multipathing also balances flows across the network as congestion builds up on certain links where ECMP on its own would risk load imbalances forming.
Where congestion does build up, the improved telemetry, which is made possible by forwarding data on lost packets to receivers, helps accelerate the process of resending data and helps to cut overall tail latency on the network. A further improvement in Ultra Ethernet is direct support for Zero-Trust security mechanisms at the transport layer. This improves the ability of systems to resist hacking attempts, no matter where they are initiated.
Considerations in AI Data Centers
The designers of AI data center networks are set to make use of adaptive architectures that can benefit from these and other protocol changes. Such architectures can better handle the dynamic data-transfer patterns that high-volume inferencing workloads experience, but it should be noted that the changes at every level of the network hierarchy implied by the improvements in raw transfer rates and protocol changes introduce extra levels of complexity and this can easily lead to unanticipated consequences.
Impaired performance and errors may result from the combination of traffic bursts and particular traffic patterns interacting with network issues that may reach down to the physical layer. At the physical layer level, the higher fiber density needed for protocols such as 1.6T can introduce issues such as crosstalk and similar forms of interference, as well as sensitivity to fiber and connector damage during installation. These can in turn lead to intermittent faults that may only be apparent under high load as devices come under higher thermal stress.
Further up the stack, there is potential for interactions between different protocols to cause performance issues, such as physical-layer issues that can in turn lead to link flapping with oscillation between active and inactive states potentially causing long-lived problems that massively reduce throughput on affected paths. Similarly, poorly set PFC thresholds can limit traffic on links needed for load balancing during periods of stress.
| Layer | Description | Function |
| 0 | Physical Medium | Governs photonic or electrical channel, covering the fiber, interconnects, and laser signal characteristics. |
| 1 | Physical | Manages delivery and capture of unstructured bit streams or symbols across the media. In HSE, this includes modulation (PAM4), error correction (FEC), and DSP. |
| 2 | Data link | Facilitates movement of data frames across a single link between hardware endpoints, specifically handling MAC addressing and data encapsulation. |
| 3 | Network | Coordinates multi-hop data movement via packets, focusing on logical IP addressing, routing, and fabric-wide congestion management. |
| 4 | Transport | Ensures the dependable transfer of data segments across the fabric, providing end-to-end flow control, error recovery, and data multiplexing. |
| 5 | Session | Regulates active connections by establishing, maintaining, and synchronizing persistent dialogue and data exchanges between systems. |
| 6 | Presentation | Formats and prepares data for the application layer; this involves critical tasks like syntax translation, data compression, and cryptographic security. |
| 7 | Application | Interfaces directly with software processes to provide high-level networking services for tasks like file transfers, remote access, and AI job coordination. |
Table 1: Summarizing the OSI Layers 0-7, with 0-3 being media layers, and 4-7 being host layers. While not officially part of the OSI layers, Layer 0 has been included as it describes the physical transmission layer that is relevant to HSE
The Need for Emulation
Because AI-focused networks will often only be seen at extremes in loading, testing at scale is vital for both training and inference processes. Furthermore, troubleshooting such issues using conventional techniques is challenging, especially as AI workloads often involve interdependencies that complicate root cause isolation with issues potentially impacting multiple components and network layers at the same time. The scale issue itself and the need to reflect real-world workloads imply you need a data center to test the network of another data center.
A more effective approach that is far easier to set up and manage is to employ hardware and software solutions specifically designed for large-scale AI accelerator and client inference emulation. For high-scale Ethernet AI fabrics validation, VIAVI TestCenter addresses AI training workload emulation while CyberFlood targets AI inference infrastructure, emulating realistic LLM user interactions at massive concurrency across the full inference stack, including API gateways, firewalls, and GPU compute capacity. Key metrics including TTFT, tokens per second, and end-to-end latency are measured in real time, while built-in security scenarios validate defenses against prompt injection and denial-of-service attacks, and GPU compute capacity, while also validating security controls against prompt injection and denial-of-service attacks.
The combination of dedicated hardware and software makes it possible to emulate not just the realistic behavior of GPUs, accelerators, and data-processing units at scale, but this combination can also mimic the requests that thousands of individual users will send to inferencing systems in parallel. These solutions provide extensive stress testing of the AI data center network with this degree of flexibility and let implementers take the advances in Ethernet technology in their stride.
To learn more, go to our AI Data Center Network testing solutions page.



{kind=link}