Speeding AI Deployment Through Simplified and Accelerated Validation
The workloads of today’s artificial intelligence (AI) applications place extraordinary demands on the quality and reliability of high-speed networks. That is true during AI training or inferencing to respond to the growing number of users issuing complex prompts, but the two broad usage models have significantly different requirements than the network connecting the thousands of computing nodes. Each brings its own complications to making a data-center network ready for AI.
In the case of training, the network must support efficient, high-bandwidth data transfers with low latency and offer tight synchronization between the nodes. Training communication frequently entails bursts of all-to-all traffic as each node broadcasts new weight values to their peers at the end of a batch of calculations. Because training cannot continue without all the parallel sub-tasks completing successfully, it demands lossless connectivity and low latency even under intense bursts of activity.
Training is not unique in its need for low latency. Inferencing requires minimal network delays to minimize the waiting time for clients. But the traffic patterns differ greatly from those found in training runs, with the network needing to serve many requests that come from outside the network as new prompts and data arrive, and also internally from the reasoning chains of “thinking” models. This is particularly the case in the new generation of large-scale mixture-of-expert systems.
AI Data Center Fabric Testing Requirements
Techniques such as load balancing to reduce bottlenecks and elastic scaling of infrastructure are vital to maintaining quality-of-service guarantees and high accelerator or GPU utilization on each computing node. A further requirement for inferencing is the need to enforce much higher levels of security and traffic monitoring because of the danger of mass attacks on AI models.
How training and inference suffer from network problems can differ dramatically. For example, a 2023 analysis of training tasks by Alibaba and Nanjing University found that less than 60% of them succeeded on the first attempt. Of those that failed, almost half were because of errors associated with the network. Important protocols developed to help implement distributed processing, such as the Collective Communications Library (CCL), employ timeouts to avoid operations becoming deadlocked. But timeouts stemming from congestion can lead to individual tasks failing. That proved to be the leading network-related factor in task failures in the study.
In addition, errors such as link flapping, where network ports were intermittently available, caused a significant number of those network failures. These errors underline the necessity for a holistic approach to network validation and testing for operators. Link flapping, for example, rarely stems from a single-layer problem. Rather it often arises from conflicting interactions between automatic optical protection and IP settings, which trigger an oscillation where links switch rapidly between active to inactive states.
In the inferencing environment, traffic patterns are far less predictable. Bursts of user activity can easily lead to congestion. This results in blocked transactions that may drive a cascade of negative effects that reduce throughput across a large part of the data center. Many systems will also be vulnerable to attacks that aim at denial of service, or which attempt to compromise AI agents at the prompt level. Operators need to examine how many different scenarios will affect the network in addition to analyzing how well the network architecture distributes work to the nodes across the data center to maximize utilization and profitability.
High-Speed Ethernet in AI Data Centers
Operators are turning to novel forms of high-speed Ethernet to help deal with the requirements of AI traffic, which focus on techniques to reduce latency by reducing the number of handshake transactions needed for connections and improvements to congestion control. Data centers may use combinations of conventional Ethernet equipment and switches that handle newer protocols like Ultra Ethernet. It will therefore be vital to ensure these systems coexist seamlessly and to identify where paths might benefit from upgrades.
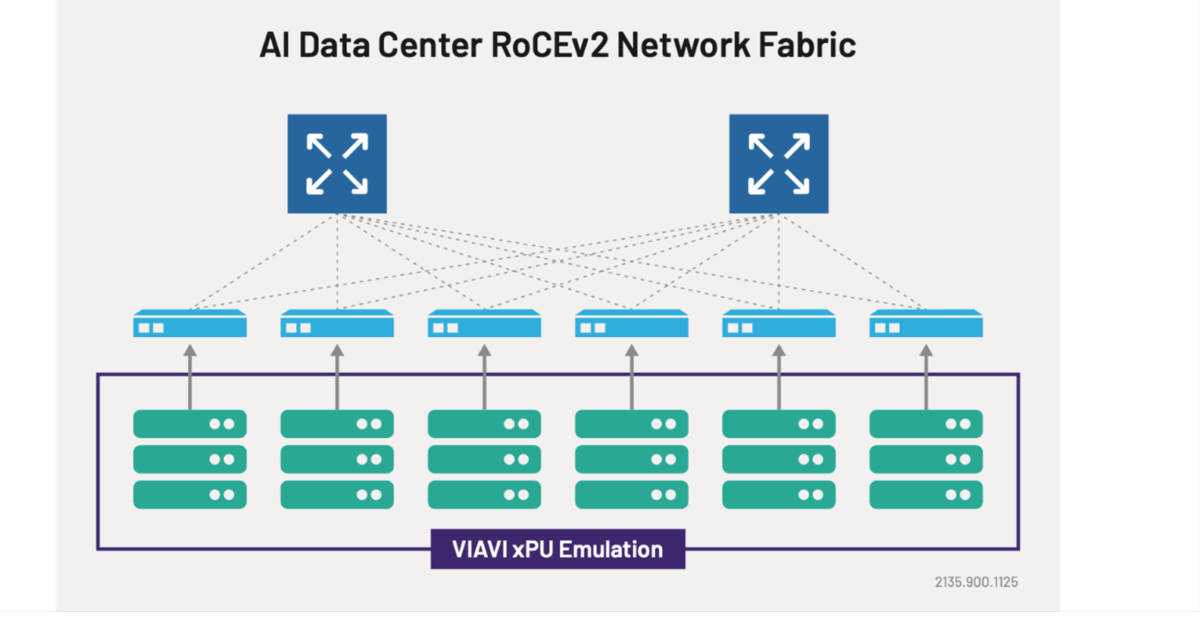
The key to handling these issues is to perform extensive validation of the network architecture and equipment used, from the physical layer up to high-level packet control. But at the scale that AI training and inferencing systems now encompass, achieving the levels of traffic required to perform extensive testing requires the test framework to be built around the many individual tests required. Some scenarios require emulation of GPUs, accelerators, and data-processing units (xPUs) to generate large amounts of inter-node traffic. Others need the ability to imitate the behavior of thousands of individual users making diverse requests in terms of prompt size and data throughput.
Testing at-scale is vital. So is test flexibility. Minor mistakes in network configurations can lead to problems that, like link flapping, do not emerge clearly until the entire system is under stress. These include seemingly simple decisions such as VLAN tagging, queue mapping, and buffer allocations that turn out to be inadequate. Each of them can silently degrade performance to the point where it becomes painfully obvious.
Take an unexpected level of packet loss during peak loads. That may be because of misconfigurations in the thresholds set for techniques like priority flow control. This allows individual flow for different data streams, but poorly chosen thresholds, just like inadequate buffers in switch ports, can cause unexpected losses during bursts. If those are synchronized events, such as training weight updates, the effects can be widespread.
Troubleshooting for 800G and 1.6T Data Center Fabrics
Of course, troubleshooting such issues using conventional techniques is challenging. The scale and interdependencies of AI workloads complicate root cause isolation, as issues often involve multiple components and network layers simultaneously. Testing infrastructure needs to be designed so that users can easily adapt to different scenarios as they track down issues. In addition, test strategies should first detect the potential for these problems and then home in on affected queues or ports.
Without specialized equipment, it would take an entire data center to exercise the target data center to the extent needed to detect these situations. A far more efficient solution is to use hardware and software built for xPU and client emulation at scale. Purpose built 800G and 1.6T testing platforms such as VIAVI TestCenter and its automation tools allow testing across varying frame sizes, data sizes, port speeds, and AI workload traffic patterns. Through advanced reporting and interactive dashboards, this combination delivers the ability to find signs of problems and assess the combinations of events that cause them to appear. The results empower network architects to fix issues and fine-tune settings.
By integrating traffic emulation, performance benchmarking, and flow-level analytics into the development and test process, network and infrastructure teams who need to create AI-ready systems are better equipped to make informed decisions and reduce risk, increasing confidence in the final deployment.
Learn more about VIAVI’s AI Data Center Network Testing solutions.




{kind=link}